
Zawartość

Źródło: Kran77 / Dreamstime.com
Na wynos:
Modele dogłębnego uczenia uczą komputery samodzielnego myślenia, z bardzo zabawnymi i interesującymi wynikami.
Głębokie uczenie się jest stosowane w coraz większej liczbie domen i branż. Od samochodów bez kierowcy, przez grę Go, po generowanie obrazów muzycznych, codziennie pojawiają się nowe modele dogłębnej nauki. Oto kilka popularnych modeli dogłębnego uczenia się. Naukowcy i programiści biorą te modele i modyfikują je w nowy i kreatywny sposób. Mamy nadzieję, że ta prezentacja zainspiruje Cię do zobaczenia, co jest możliwe. (Aby dowiedzieć się o postępach w sztucznej inteligencji, zobacz Czy komputery będą w stanie naśladować ludzki mózg?)
Styl neuronowy
Nie możesz poprawić swoich umiejętności programistycznych, gdy nikt nie dba o jakość oprogramowania.
Neuralny Narrator

Neural Storyteller to model, który po otrzymaniu obrazu może wygenerować romantyczną historię o obrazie. To zabawna zabawka, a jednak możesz sobie wyobrazić przyszłość i zobaczyć, w jakim kierunku poruszają się te wszystkie modele sztucznej inteligencji.

Powyższa funkcja to operacja „zmiany stylu”, która pozwala modelowi przenieść standardowe podpisy obrazów do stylu opowiadań z powieści. Zmiana stylu została zainspirowana „Neural Algorytmem stylu artystycznego”.
Dane
Istnieją dwa główne źródła danych, które są wykorzystywane w tym modelu. MSCOCO to zestaw danych firmy Microsoft zawierający około 300 000 obrazów, z których każdy zawiera pięć podpisów. MSCOCO to jedyne używane dane nadzorowane, co oznacza, że są to jedyne dane, do których ludzie musieli wejść i wyraźnie napisać podpisy dla każdego obrazu.
Jednym z głównych ograniczeń sieci neuronowej ze sprzężeniem zwrotnym jest brak pamięci. Każda prognoza jest niezależna od poprzednich obliczeń, tak jakby była to pierwsza i jedyna prognoza, jaką kiedykolwiek stworzyła sieć. Jednak w przypadku wielu zadań, takich jak tłumaczenie zdania lub akapitu, dane wejściowe powinny składać się z sekwencyjnych i powiązanych ze sobą danych. Na przykład trudno byłoby zrozumieć jedno słowo w zdaniu bez konsensów zawartych w otaczających słowach.
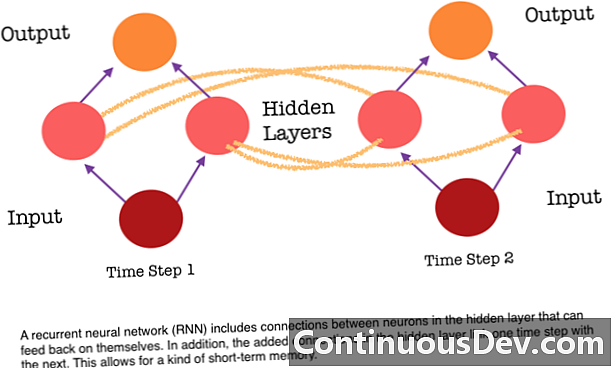
RNN są różne, ponieważ dodają kolejny zestaw połączeń między neuronami. Łącza te pozwalają aktywacjom z neuronów w ukrytej warstwie na powrót do siebie na następnym etapie sekwencji. Innymi słowy, na każdym etapie warstwa ukryta otrzymuje zarówno aktywację z warstwy poniżej, jak i z poprzedniego kroku w sekwencji. Ta struktura zasadniczo zapewnia pamięć cyklicznych sieci neuronowych. W związku z tym w celu wykrycia obiektu RNN może wykorzystać swoje wcześniejsze klasyfikacje psów, aby ustalić, czy obecny obraz jest psem.
Char-RNN TED
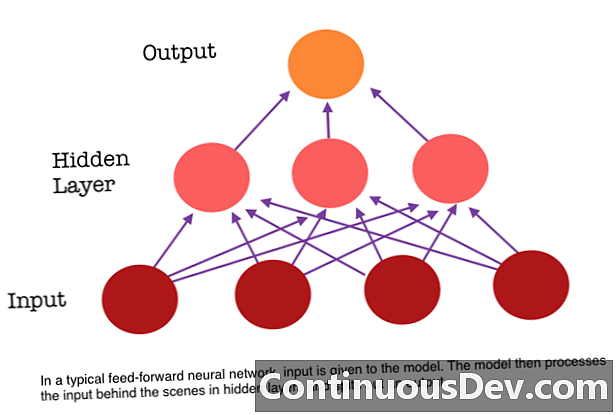
Ta elastyczna struktura w ukrytej warstwie pozwala RNN być bardzo dobrym rozwiązaniem dla modeli językowych na poziomie znaków. Char RNN, pierwotnie stworzony przez Andreja Karpathy'ego, to model, który pobiera jeden plik jako dane wejściowe i trenuje RNN, aby nauczyć się przewidywać następny znak w sekwencji. RNN może generować znak po znaku, który będzie wyglądał jak oryginalne dane treningowe. Demo zostało przeszkolone przy użyciu transkrypcji różnych rozmów TED. Nakarm model jednym lub kilkoma słowami kluczowymi, a wygeneruje fragment o słowach kluczowych w głosie / stylu TED Talk.
Wniosek
Modele te pokazują nowe przełomy w inteligencji maszyn, które stały się możliwe dzięki głębokiemu uczeniu się. Dogłębne uczenie się pokazuje, że możemy rozwiązać problemy, których nigdy wcześniej nie mogliśmy rozwiązać, i nie osiągnęliśmy jeszcze tego płaskowyżu. Spodziewaj się, że w ciągu najbliższych kilku lat zobaczysz wiele bardziej ekscytujących rzeczy, takich jak samochody bez kierowców, dzięki innowacjom dogłębnego uczenia się.