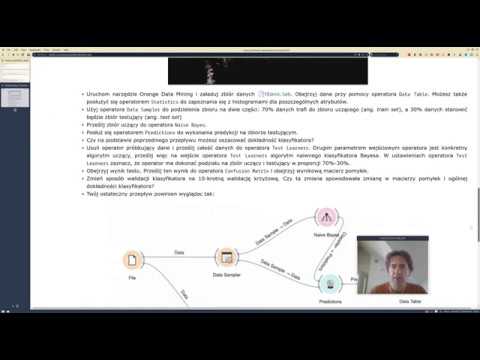
Zawartość
- Definicja - Co oznacza Naive Bayes?
- Wprowadzenie do Microsoft Azure i Microsoft Cloud | W tym przewodniku dowiesz się, na czym polega przetwarzanie w chmurze i jak Microsoft Azure może pomóc w migracji i prowadzeniu firmy z chmury.
- Techopedia wyjaśnia Naive Bayes
Definicja - Co oznacza Naive Bayes?
Naiwny klasyfikator Bayesa jest algorytmem wykorzystującym twierdzenie Bayesa do klasyfikowania obiektów. Naiwne klasyfikatory Bayesa zakładają silną lub naiwną niezależność między atrybutami punktów danych. Popularne zastosowania naiwnych klasyfikatorów Bayes obejmują filtry antyspamowe, analizy i diagnostykę medyczną. Te klasyfikatory są szeroko stosowane w uczeniu maszynowym, ponieważ są łatwe do wdrożenia.
Naiwny Bayes jest również znany jako prosty Bayes lub Bayes niezależności.
Wprowadzenie do Microsoft Azure i Microsoft Cloud | W tym przewodniku dowiesz się, na czym polega przetwarzanie w chmurze i jak Microsoft Azure może pomóc w migracji i prowadzeniu firmy z chmury.
Techopedia wyjaśnia Naive Bayes
Naiwny klasyfikator Bayesa wykorzystuje teorię prawdopodobieństwa do klasyfikowania danych. Naiwne algorytmy klasyfikujące Bayesa wykorzystują twierdzenie Bayesa. Kluczowym wnioskiem z twierdzenia Bayesa jest to, że prawdopodobieństwo zdarzenia można dostosować w miarę wprowadzania nowych danych.
To, co czyni naiwnym klasyfikator Bayesa naiwnym, to jego założenie, że wszystkie atrybuty rozważanego punktu danych są od siebie niezależne. Klasyfikator sortujący owoce na jabłka i pomarańcze wiedziałby, że jabłka są czerwone, okrągłe i mają określony rozmiar, ale nie przyjąłby wszystkich tych rzeczy naraz. W końcu pomarańcze też są okrągłe.
Naiwny klasyfikator Bayesa nie jest pojedynczym algorytmem, ale rodziną algorytmów uczenia maszynowego, które wykorzystują niezależność statystyczną. Algorytmy te są stosunkowo łatwe do napisania i działają wydajniej niż bardziej złożone algorytmy Bayesa.
Najpopularniejszą aplikacją są filtry antyspamowe. Filtr antyspamowy sprawdza s dla określonych słów kluczowych i umieszcza je w folderze spamu, jeśli są do siebie dopasowane.
Pomimo nazwy, im więcej danych otrzymuje, tym dokładniejszy staje się naiwny klasyfikator Bayesa, na przykład od użytkownika oznaczającego s w skrzynce odbiorczej spamu.