Zawartość
- Klub sceptyków
- Konwolucyjne sieci neuronowe (CNN)
- Bez błędów, bez stresu - Twój przewodnik krok po kroku do tworzenia oprogramowania zmieniającego życie bez niszczenia życia
- Jednostki długoterminowej pamięci krótkotrwałej (LSTM)
- Generative Adversarial Networks (GAN)
- Wnioski

Źródło: Vs1489 / Dreamstime.com
Na wynos:
Czy „głębokie uczenie się” to tylko inna nazwa zaawansowanych sieci neuronowych, czy może jest w tym coś więcej? Przyjrzymy się najnowszym osiągnięciom w głębokim uczeniu się, a także sieciom neuronowym.
Klub sceptyków
Jeśli, tak jak ja, należysz do klubu sceptyków, mógłbyś również zastanawiać się, o co tyle zamieszania w głębokim uczeniu się. Sieci neuronowe (NN) nie są nową koncepcją. Wielowarstwowy perceptron został wprowadzony w 1961 roku, co nie jest dokładnie wczoraj.
Ale obecne sieci neuronowe są bardziej złożone niż tylko perceptron wielowarstwowy; mogą mieć o wiele więcej ukrytych warstw, a nawet powtarzających się połączeń. Ale poczekaj, czy nadal nie używają algorytmu propagacji wstecznej do treningu?
Tak! Teraz moc obliczeniowa maszyny jest nieporównywalna z tym, co było dostępne w latach 60., a nawet w latach 80. Oznacza to, że o wiele bardziej złożone architektury neuronowe można trenować w rozsądnym czasie.
Jeśli więc koncepcja nie jest nowa, czy może to oznaczać, że głębokie uczenie się to tylko garść sieci neuronowych na sterydach? Czy całe zamieszanie wynika po prostu z obliczeń równoległych i wydajniejszych maszyn? Często, gdy badam tak zwane rozwiązania głębokiego uczenia się, tak to wygląda. (Jakie są praktyczne zastosowania sieci neuronowych w świecie rzeczywistym? Dowiedz się w 5 przypadkach użycia sieci neuronowych, które pomogą Ci lepiej zrozumieć technologię).
Jak już powiedziałem, należę do klubu sceptyków i zwykle obawiam się dowodów, które nie zostały jeszcze poparte. Tym razem odłóżmy na bok uprzedzenia i spróbujmy dogłębnie zbadać nowe techniki głębokiego uczenia się w odniesieniu do sieci neuronowych, jeśli takie istnieją.
Podczas kopania nieco głębiej znajdujemy kilka nowych jednostek, architektur i technik w dziedzinie głębokiego uczenia się. Niektóre z tych innowacji mają mniejszą wagę, jak na przykład randomizacja wprowadzana przez warstwę usuwającą. Niektóre inne są jednak odpowiedzialne za ważniejsze zmiany. I z pewnością większość z nich polega na większej dostępności zasobów obliczeniowych, ponieważ są one dość drogie obliczeniowo.
Moim zdaniem w dziedzinie sieci neuronowych pojawiły się trzy główne innowacje, które znacznie przyczyniły się do zdobycia przez nią głębokiego uczenia się: sieci neuronowe zwojowe (CNN), jednostki pamięci krótkotrwałej (LSTM) i generatywne sieci przeciwne (GAN) ).
Konwolucyjne sieci neuronowe (CNN)
Wielki wybuch głębokiego uczenia się - a przynajmniej kiedy po raz pierwszy usłyszałem boom - miał miejsce w projekcie rozpoznawania obrazów, ImageNet Large Scale Visual Recognition Challenge, w 2012 roku. Aby automatycznie rozpoznać obrazy, splotowa sieć neuronowa z zastosowano osiem warstw - AlexNet. Pierwsze pięć warstw było warstwami splotowymi, niektóre z nich poprzedzone były warstwami o maksymalnej puli, a ostatnie trzy warstwy były w pełni połączonymi warstwami, wszystkie z nienasyconą funkcją aktywacji ReLU. Sieć AlexNet osiągnęła błąd w pierwszej piątce wynoszący 15,3%, czyli o ponad 10,8 punktu procentowego mniej niż drugi. To było wielkie osiągnięcie!
Bez błędów, bez stresu - Twój przewodnik krok po kroku do tworzenia oprogramowania zmieniającego życie bez niszczenia życia

Nie możesz poprawić swoich umiejętności programistycznych, gdy nikt nie dba o jakość oprogramowania.
Oprócz architektury wielowarstwowej największą innowacją AlexNet była warstwa splotowa.
Pierwsza warstwa w sieci splotowej jest zawsze warstwą splotową. Każdy neuron w warstwie splotowej skupia się na określonym obszarze (polu odbiorczym) obrazu wejściowego i poprzez jego ważone połączenia działa jako filtr dla pola odbiorczego. Po przesunięciu filtra, neuron za neuronem, na wszystkie pola odbiorcze obrazu, wyjście warstwy splotowej tworzy mapę aktywacji lub mapę cech, które mogą być użyte jako identyfikator cech.
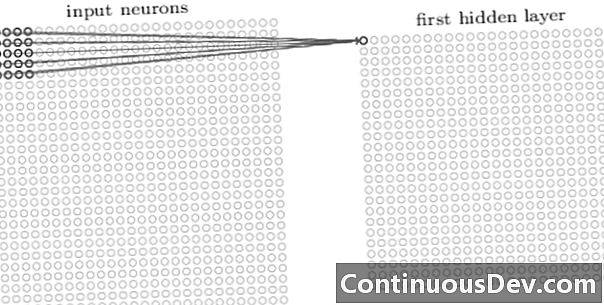
Dodając na siebie więcej warstw splotowych, mapa aktywacji może przedstawiać coraz bardziej złożone elementy z obrazu wejściowego. Ponadto, często w architekturze splotowej sieci neuronowej, kilka kolejnych warstw jest przeplatanych między tymi wszystkimi warstwami splotowymi, aby zwiększyć nieliniowość funkcji mapowania, poprawić niezawodność sieci i kontrolować nadmierne dopasowanie.
Teraz, gdy możemy wykryć funkcje wysokiego poziomu z obrazu wejściowego, możemy dodać jedną lub więcej w pełni połączonych warstw na końcu sieci w celu tradycyjnej klasyfikacji. Ta ostatnia część sieci przyjmuje dane wyjściowe warstw splotowych jako dane wejściowe i generuje wektor N-wymiarowy, gdzie N jest liczbą klas. Każda liczba w tym N-wymiarowym wektorze reprezentuje prawdopodobieństwo klasy.
Wcześniej często słyszałem sprzeciw wobec sieci neuronowych dotyczący braku przejrzystości ich architektury oraz niemożności interpretacji i wyjaśnienia wyników. Sprzeciw ten pojawia się coraz rzadziej w związku z sieciami głębokiego uczenia się. Wygląda na to, że teraz można zaakceptować wymianę efektu czarnej skrzynki na większą dokładność klasyfikacji.
Jednostki długoterminowej pamięci krótkotrwałej (LSTM)
Kolejną dużą poprawę uzyskaną dzięki głębokiemu uczeniu się sieci neuronowych zaobserwowano w analizie szeregów czasowych za pomocą rekurencyjnych sieci neuronowych (RNN).
Nawracające sieci neuronowe nie są nową koncepcją. Były one już używane w latach 90. i szkolone z algorytmem propagacji wstecznej w czasie (BPTT). Jednak w latach 90. szkolenie ich było często niemożliwe z uwagi na wymaganą ilość zasobów obliczeniowych. Jednak obecnie, ze względu na wzrost dostępnej mocy obliczeniowej, stało się możliwe nie tylko szkolenie RNN, ale także zwiększenie złożoności ich architektury. Czy to wszystko? Oczywiście, że nie.
W 1997 r. Wprowadzono specjalną jednostkę neuronową, aby lepiej radzić sobie z zapamiętywaniem odpowiedniej przeszłości w szeregu czasowym: jednostka LSTM. Dzięki kombinacji wewnętrznych bram, jednostka LSTM jest w stanie zapamiętać istotne informacje z przeszłości lub zapomnieć o nieistotnej przeszłości w szeregu czasowym. Sieć LSTM to specjalny typ rekurencyjnej sieci neuronowej, w tym jednostki LSTM. Rozłożoną wersję RNN opartego na LSTM pokazano na rysunku 2.
Aby przezwyciężyć problem ograniczonej pojemności długiej pamięci, jednostki LSTM używają dodatkowego stanu ukrytego - stanu komórki C (t) - pochodzi z pierwotnego stanu ukrytego h (t). C (t) reprezentuje pamięć sieciową. Szczególna struktura, zwana bramkami, pozwala usunąć (zapomnieć) lub dodać (zapamiętać) informacje do stanu komórki C (t) na każdym etapie w oparciu o wartości wejściowe x (t) i poprzedni stan ukryty h (t − 1). Każda bramka decyduje, które informacje dodać lub usunąć, wyprowadzając wartości od 0 do 1. Mnożąc wyjście bramkowe punktowo przez stan komórki C (t − 1), informacja jest usuwana (wyjście bramki = 0) lub zachowane (wyjście bramki = 1).
Na ryc. 2 widzimy strukturę sieci jednostki LSTM. Każda jednostka LSTM ma trzy bramki. „Zapomnij warstwę bramki” na początku odfiltrowuje informacje z poprzedniego stanu komórki C (t − 1) na podstawie bieżącego wejścia x (t) i stan ukryty poprzedniej komórki h (t − 1). Następnie kombinacja „wejściowej warstwy bramkowej” i „warstwy tanh” decyduje, które informacje dodać do poprzedniego, już odfiltrowanego stanu komórki C (t − 1). Wreszcie ostatnia bramka, „bramka wyjściowa”, decyduje, która z informacji ze zaktualizowanego stanu komórki C (t) kończy się w kolejnym stanie ukrytym h (t).
Aby uzyskać więcej informacji na temat jednostek LSTM, sprawdź post na blogu GitHub „Understanding LSTM Networks” autorstwa Christophera Olaha.
Ryc. 2. Struktura komórki LSTM (odtworzona z „Deep Learning” Iana Goodfellowa, Yoshua Bengio i Aarona Courville'a). Zwróć uwagę na trzy bramki w jednostkach LSTM. Od lewej do prawej: brama zapomnienia, brama wejściowa i bramka wyjściowa.
Jednostki LSTM zostały z powodzeniem wykorzystane w wielu problemach z prognozowaniem szeregów czasowych, ale szczególnie w rozpoznawaniu mowy, przetwarzaniu języka naturalnego (NLP) i generowaniu swobodnym.
Generative Adversarial Networks (GAN)

Generatywna sieć przeciwników (GAN) składa się z dwóch sieci głębokiego uczenia się, generatora i dyskryminatora.
Generator sol to transformacja, która przekształca szum wejściowy z w tensor - zwykle obraz - x (x= G (z)). DCGAN jest jednym z najpopularniejszych projektów sieci generatorów. W sieciach CycleGAN generator wykonuje wiele transponowanych zwojów do próbkowania z aby ostatecznie wygenerować obraz x (Ryc. 3).
Wygenerowany obraz x jest następnie wprowadzany do sieci dyskryminacyjnej. Sieć dyskryminatora sprawdza rzeczywiste obrazy w zestawie szkoleniowym oraz obraz generowany przez sieć generatorów i generuje dane wyjściowe RE(x), co jest prawdopodobieństwem tego obrazu x jest realne.
Generator i dyskryminator są szkoleni przy użyciu algorytmu wstecznej propagacji do tworzenia RE(x)=1 dla wygenerowanych obrazów. Obie sieci są szkolone na przemian, konkurując ze sobą, aby się poprawić. Model GAN ostatecznie zbiega się i tworzy obrazy, które wyglądają realnie.

Sieci GAN zostały z powodzeniem zastosowane do tensorów obrazu w celu stworzenia anime, postaci ludzkich, a nawet arcydzieł podobnych do van Gogha. (W przypadku innych współczesnych zastosowań sieci neuronowych zobacz 6 dużych postępów, które możesz przypisać sztucznym sieciom neuronowym.)
Wnioski
Czy głębokie uczenie się to tylko sieć neuronowa na sterydach? Częściowo.
Chociaż jest niezaprzeczalne, że szybsze działanie sprzętu przyczyniło się w dużej mierze do udanego szkolenia bardziej złożonych, wielowarstwowych, a nawet cyklicznych architektur neuronowych, prawdą jest również to, że zaproponowano szereg nowych innowacyjnych jednostek neuronowych i architektur w dziedzinie tego, co nazywa się teraz głębokim uczeniem się.
W szczególności zidentyfikowaliśmy warstwy splotowe w CNN, jednostkach LSTM i GAN jako jedne z najbardziej znaczących innowacji w dziedzinie przetwarzania obrazu, analizy szeregów czasowych i generowania swobodnego.
Jedyne, co pozostało do zrobienia w tym momencie, to głębsze nurkowanie i dowiedz się więcej o tym, w jaki sposób sieci głębokiego uczenia mogą pomóc nam w nowych solidnych rozwiązaniach dla naszych własnych problemów z danymi.